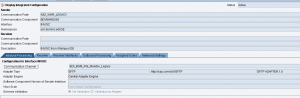
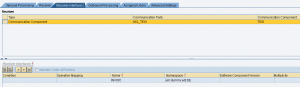
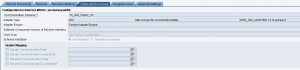
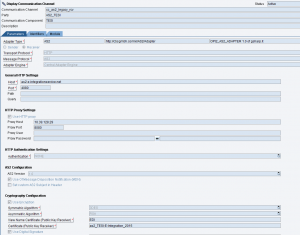
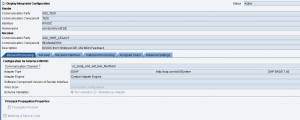
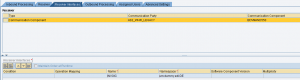
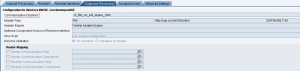
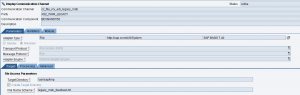
Si sta inviando un IDoc custom ad un canale receiver di tipo IDoc_AAE.
Effetto
L’invio del messaggio fallisce nel channel monitor con il seguente errore:
Error before sending due to IDoc parsing error: (7) IDOC_ERROR_PARSE_FAILURE: An IDocConversionException occurred while parsing IDocXML for type <IDoc_type>: state=READING_FIELD_VALUE_TAG, charPosition=…, lineNumber=…, columnNumber=…
Soluzione
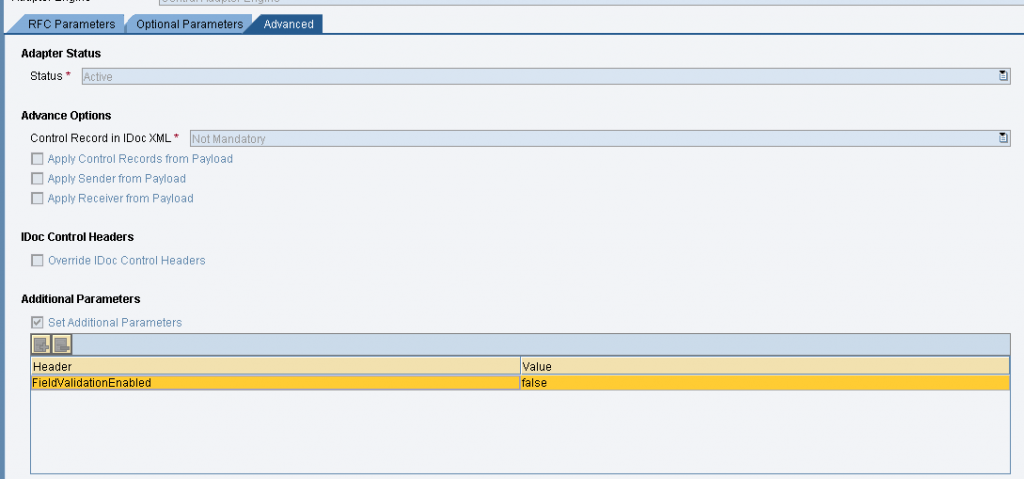
Applicare la nota 2036878 – IDoc_AAE: Disable field datatype validation during IDoc-XML parsing che suggerisce di inserire il parametro FieldValidationEnabled fra gli Additional Parameters del canale e attribuirgli il valore false.
Il parametro disabilita il controllo del DataType dell’idoc, generato in maniera non conforme dall’adapter Idoc-AAE.
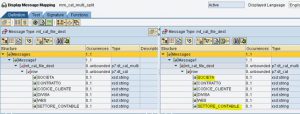
In un mapping già configurato in repository e directory, si cambia la cardinalità del messaggio da 1:1 a 1:n.
Effetto
L’esecuzione del messaggio fallisce nel channel monitor con l’errore
Adding control record to payload failed due to IDoc structure of incoming message is not correct – element IDOC has no non-whitespace child elements
Soluzione
Oltre a cambiare la cardinalità del message mapping e nell’operation mapping occorre reimportare l’operation mapping nella Interface Determination dello scenario.
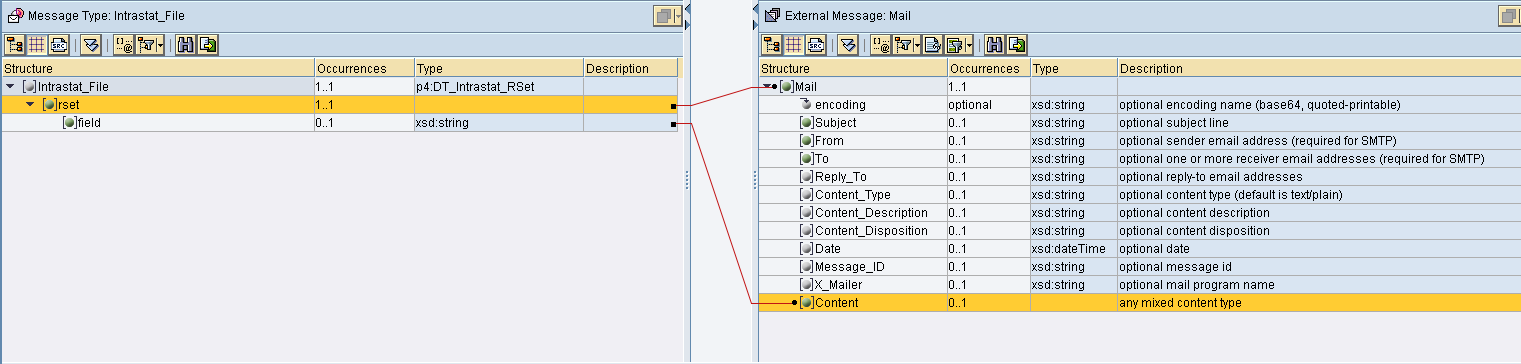
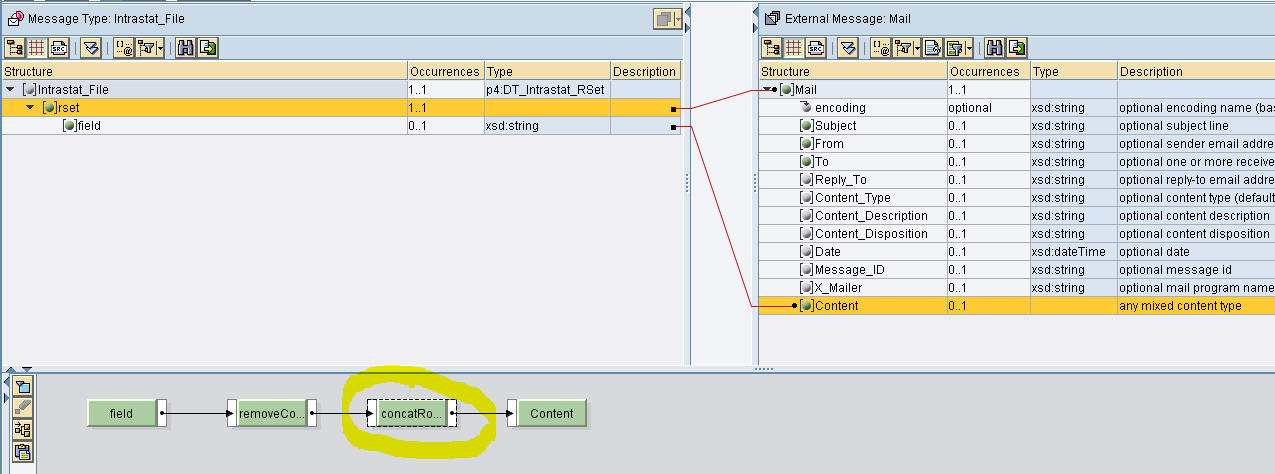
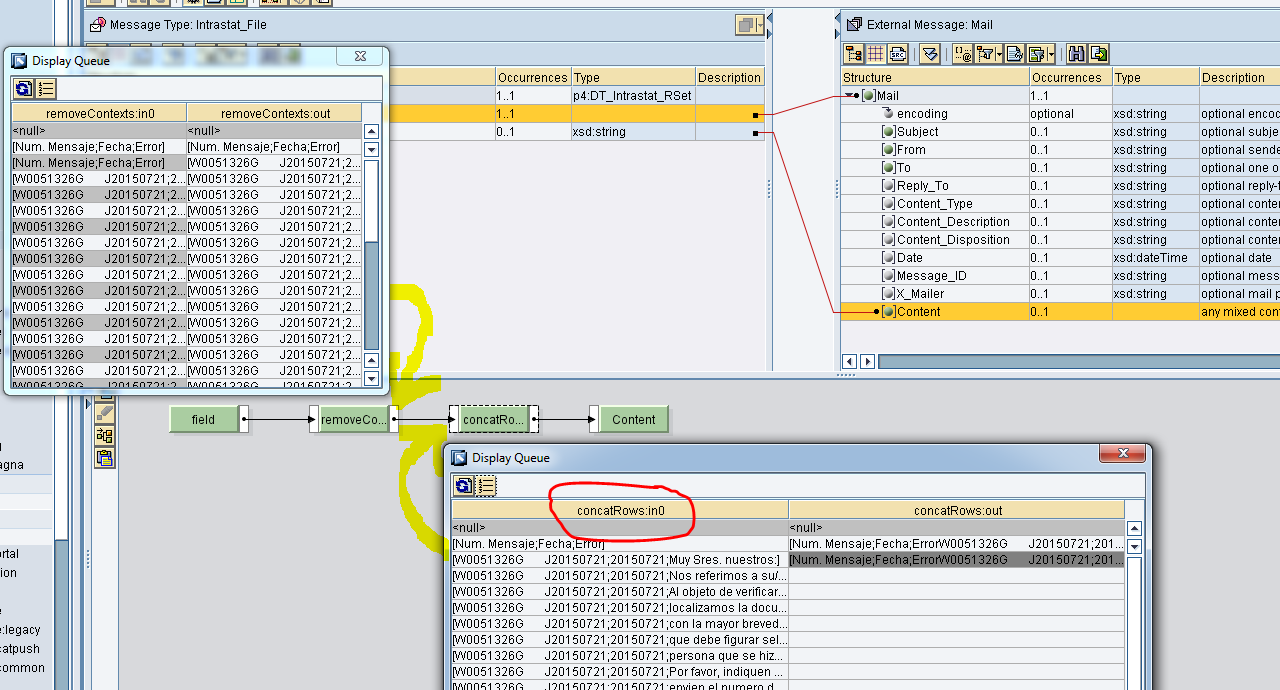
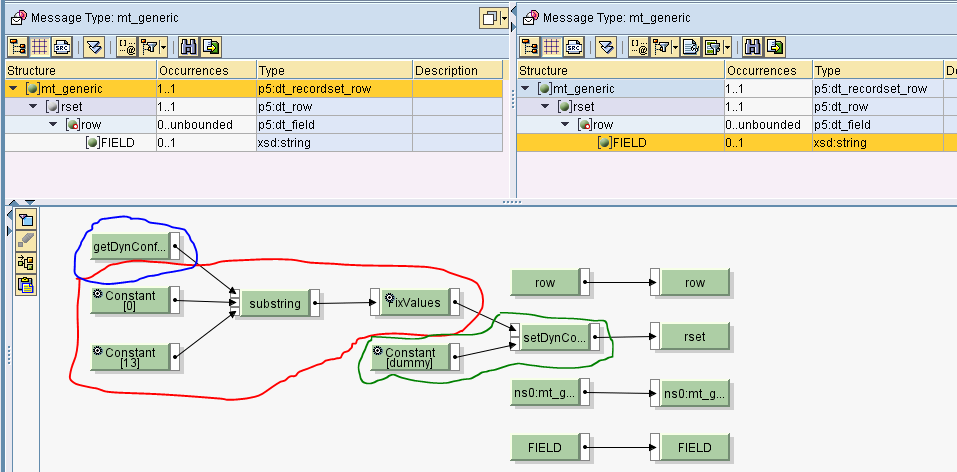
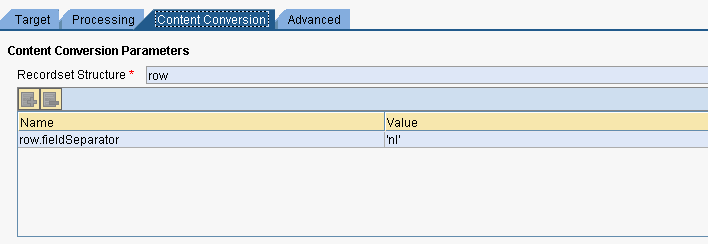
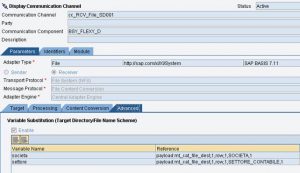
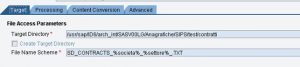
Il seguente mapping converte il contesto in un’unica stringa in cui ogni elemento di context diventa una riga.
La stringa viene mossa in Content.
L’UDF concatRows converte l’array in una stringa in cui gli elementi dell’array sono separati tramite new line.
public void concatRows(String[] rows, ResultList result, Container container) throws StreamTransformationException{
String t = "";
for (int i = 0; i < rows.length; i++) {
if (i > 0) {
t += System.getProperty("line.separator") + rows[i];
} else {
t += rows[i];
}
}
result.addValue(t);
}
Integration Builder
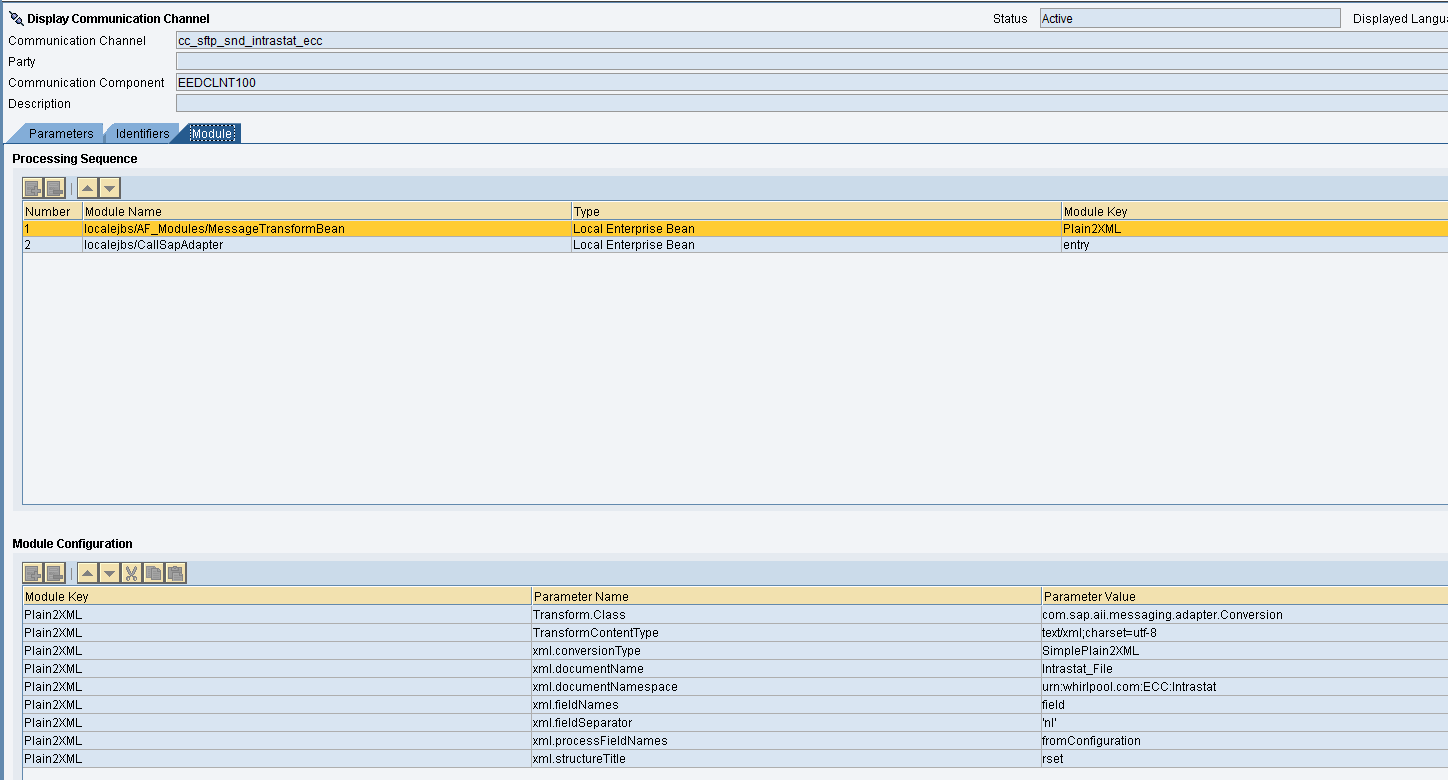
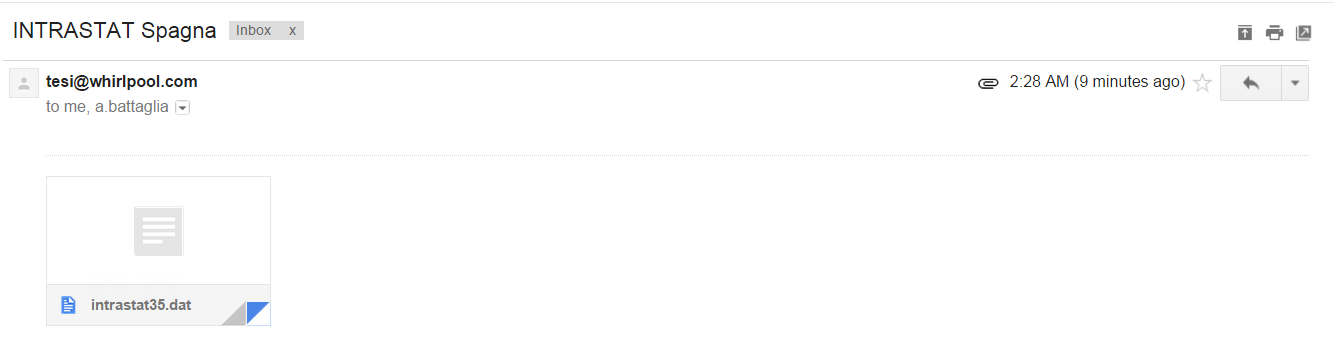
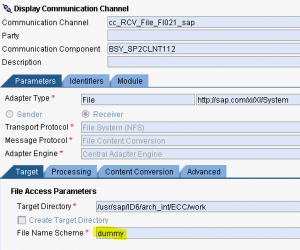
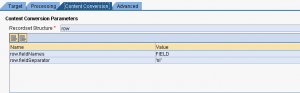
Il canale sender file
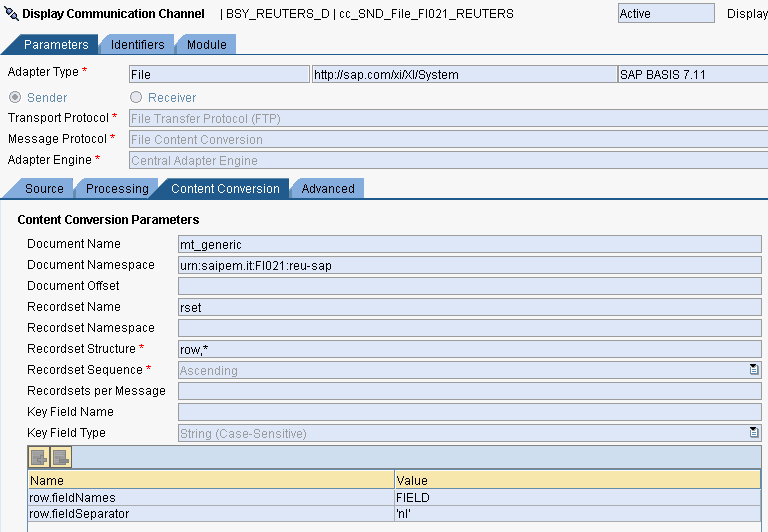
Nel caso in cui l’Adapter sender non preveda il tab Content Convertion (per esempio l’SFTP) si può adottare il modulo AF_Modules/MessageTransformBean
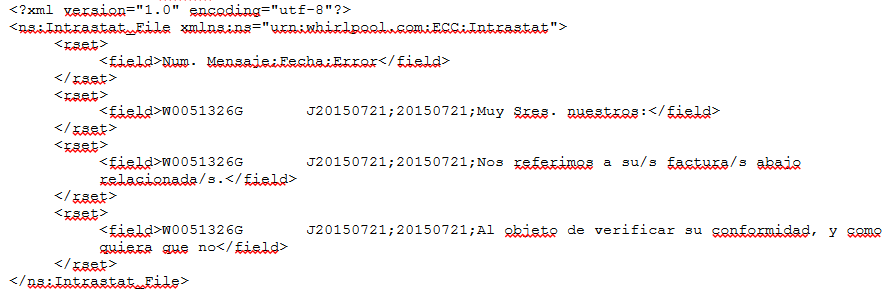
In questo caso, il file letto
Num. Mensaje;Fecha;Error
W0051326G J20150721;20150721;Muy Sres. nuestros:
W0051326G J20150721;20150721;Nos referimos a su/s factura/s abajo relacionada/s.
W0051326G J20150721;20150721;Al objeto de verificar su conformidad, y como quiera que no
assume il seguente payload
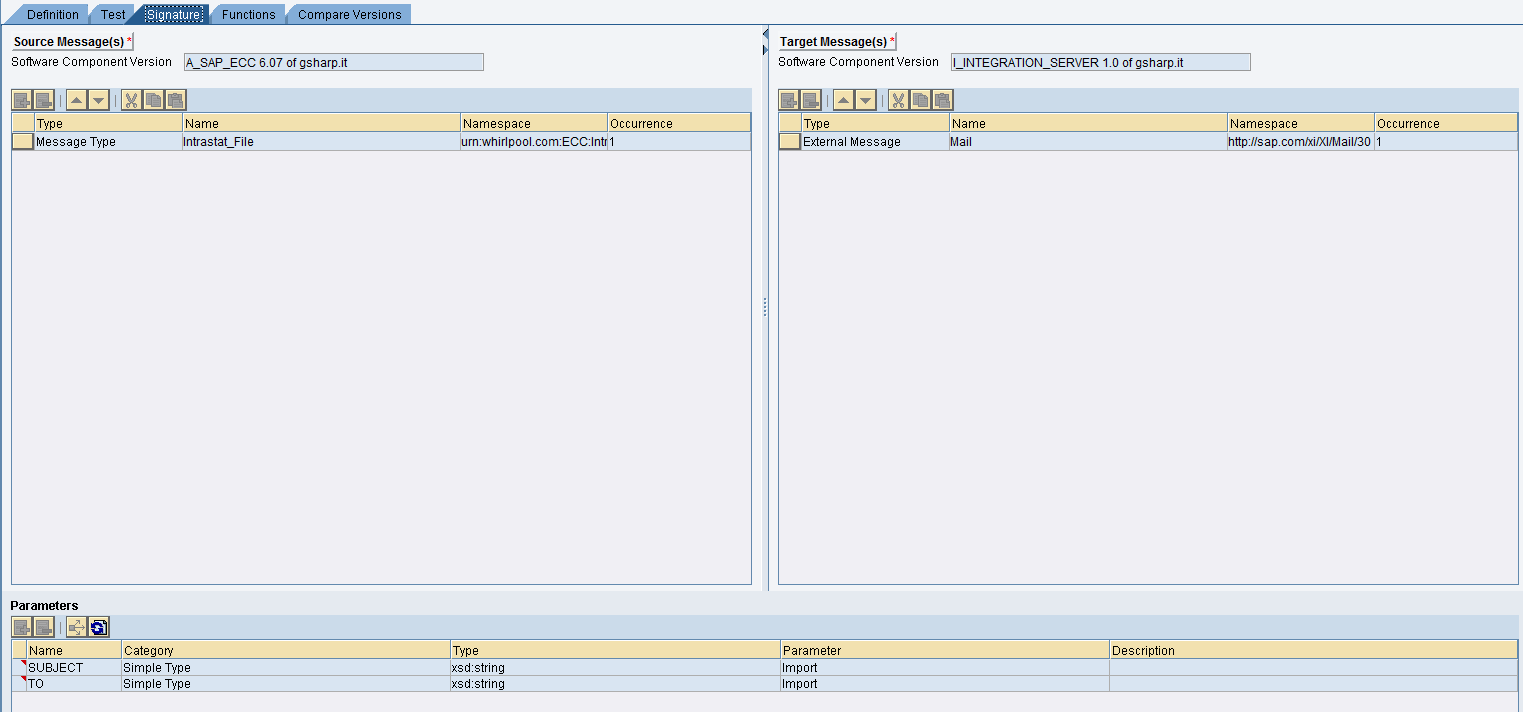
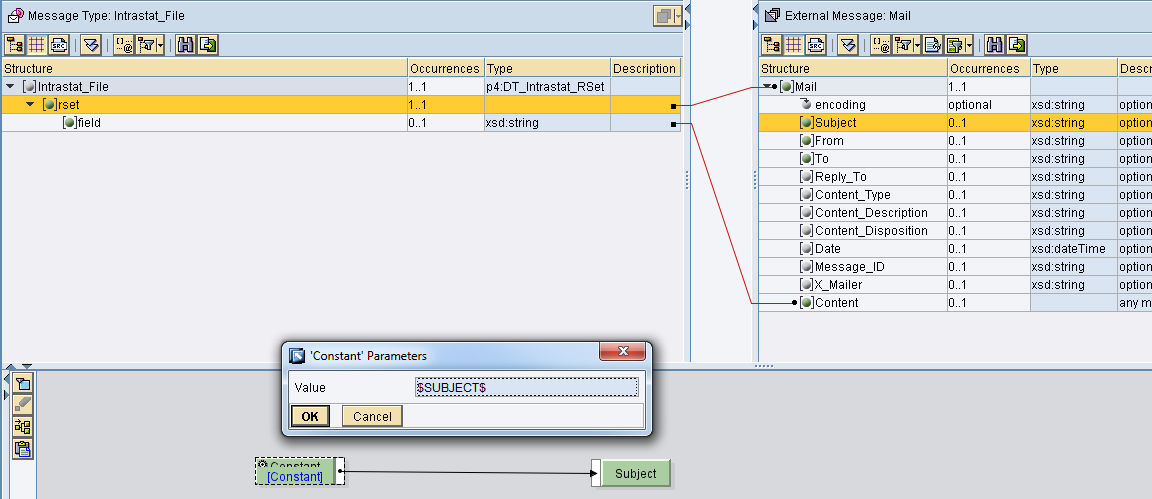
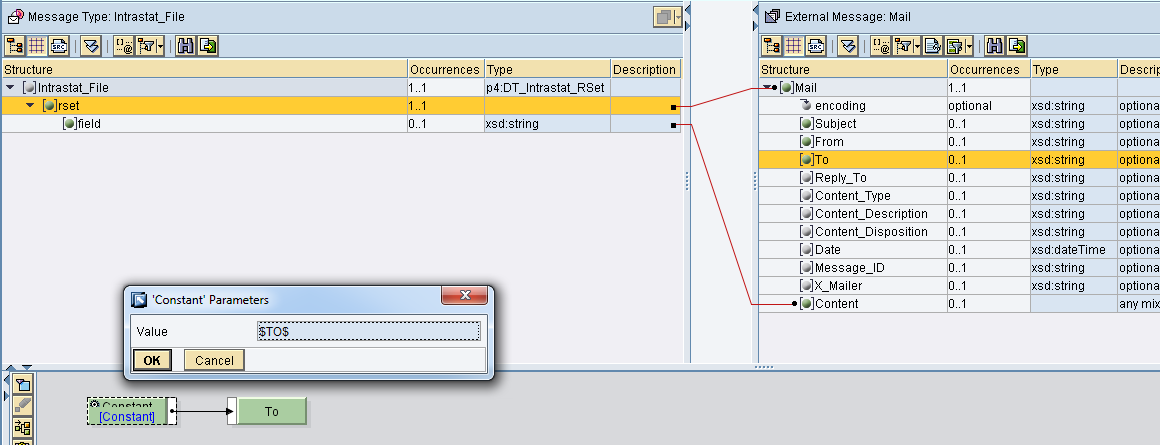
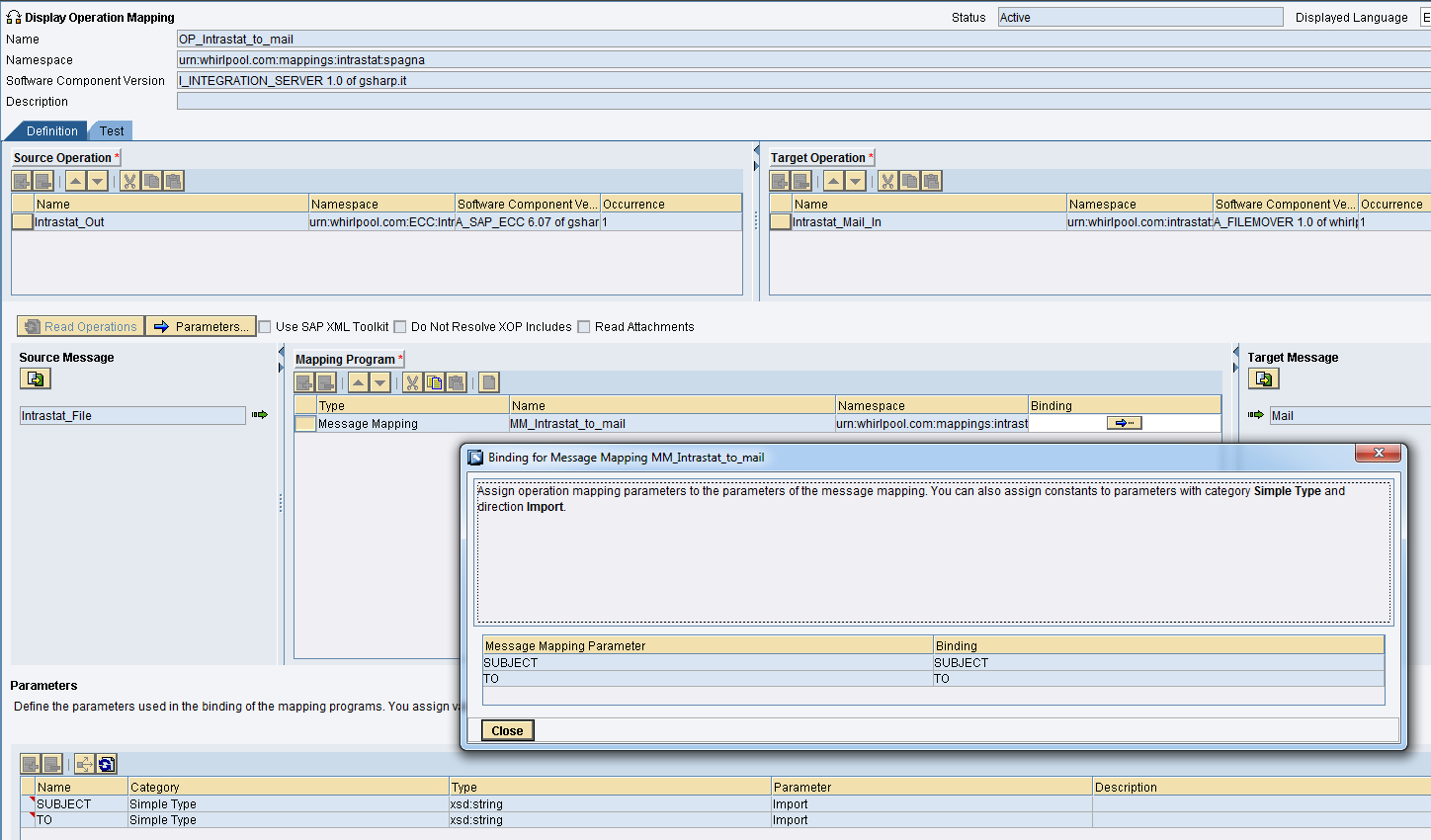
Il canale receiver mail
I parametri della mail devono essere assunti dal mapping e quini impostare Using Mail Package.
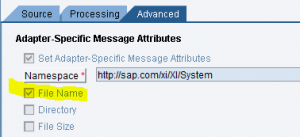
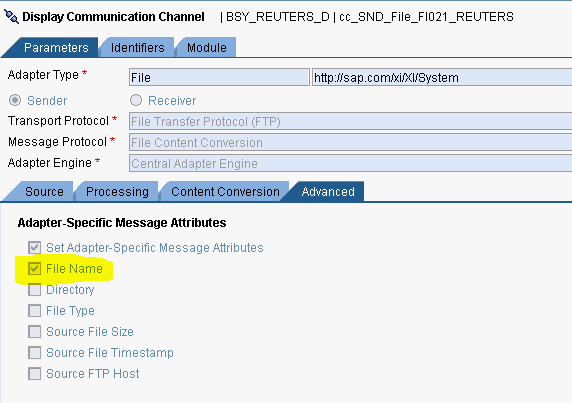
Prerequisito perché il file in attach abbia il nome del file di turno
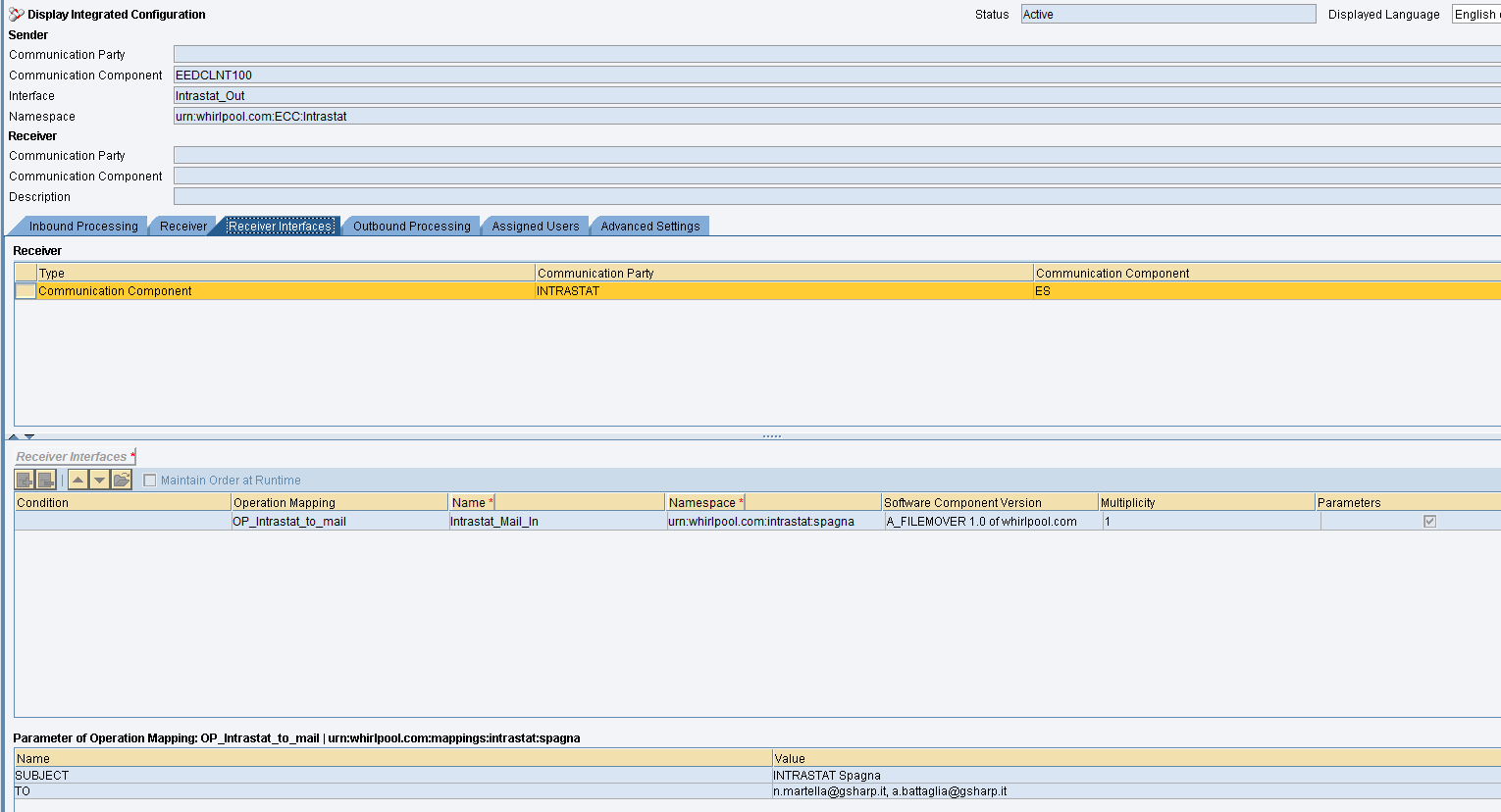
La Receiver Interface
Il test
Limitazioni
Se il canale sender è configurato per leggere più file, questi verranno inviati come attach in mail separate.
La presente soluzione gestisce solo file di testo e non anche file binary.
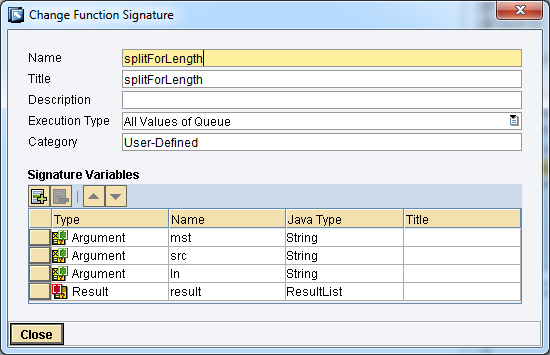
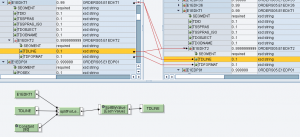
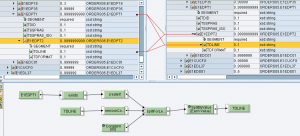
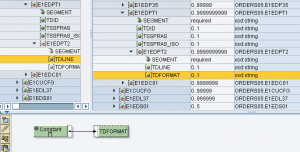
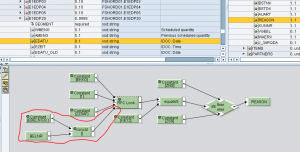
In un contesto di generazione IDoc verso ECC, occorre generare i segmenti di testo E1EDT01/E1EDT02 e/o E1EDP01/E1EDP02 partendo da una stringa in ingresso.
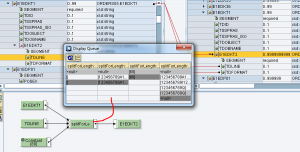
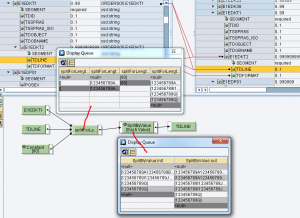
l’UDF splitForLength() è utile nella generazione dei segmenti di testo negli idoc sia nella sezione testata E1EDKT1/E1EDKT2 che in quella di posizione E1EDPT1/E1EDPT2
In particolare, l’UDF consente di generare tanti contesti E1ED*T2 quante sono le sottostringhe di src che si ottengono dividendola per la lunghezza ln.
public void splitForLength(String[] mst, String[] src, String[] ln, ResultList result, Container container) throws StreamTransformationException{
/*
@Author: Nicola Martella | www.nick4name.eu
Genera un context (ResultList) sulla base dello splitting della stringa src in tante sottostringhe quante ne occorrono dividendola per la
lunghezza indicata in ln.
La funzione gestisce i contesti multipli su mst e src.
*/
AbstractTrace _trc = container.getTrace();
// _trc.addWarning(source.substring(s, s + len)); //*******************
int len = Integer.parseInt(ln[0]);
result.clear();
int isrc = -1;
for (int imst=0; imst < mst.length; imst++){
if (mst[imst].equals(ResultList.SUPPRESS)){
result.addSuppress();
} else if (mst[imst].equals(ResultList.CC)) {
//
} else {
isrc++;
String source = src[isrc];
if (!source.equals("")){
if (len >= source.length()){
result.addValue(source);
} else {
int e = source.length() / len;
e = ((source.length() % len) > 0 ? e + 1 : e);
int s = 0;
for (int i = 0; i < e; i++){
if (source.length() - s > len){
result.addValue(source.substring(s, s + len));
} else {
result.addValue(source.substring(s));
}
s += len;
}
}
result.addContextChange();
}
}
}
return;
}
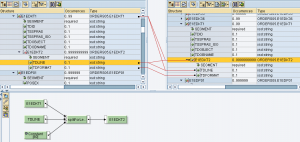
Implementazione per testi di testata
Questo genera le occorrenze di E1EDKT2 sulla base del numero di sottostringhe di TDLINE
Questo, per ciascun contesto, effettua lo splitting di TDLINE in ingresso e scrive le sottostringhe prodotte nei campi TDLINE in uscita.
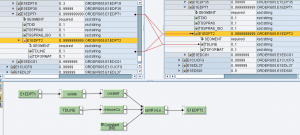
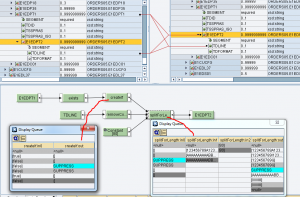
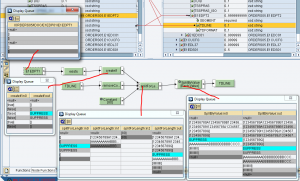
Implementazione per testi di posizione
Questo genera le occorrenze di E1EDPT2 sulla base del numero di sottostringhe di TDLINE
Questo, per ciascun contesto, effettua lo splitting di TDLINE in ingresso e scrive le sottostringhe prodotte nei campi TDLINE in uscita.
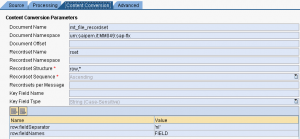
Nel seguente esempio, il contesto in entrata all’UDF – 1mo param, è così configurato:
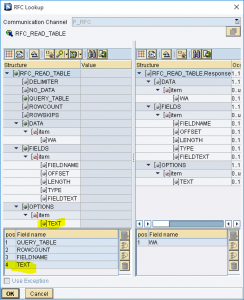
E’ possibile utilizzare la function standard RFC_READ_TABLE per leggere qualunque tabella di dictionary. Di seguito, un esempio di valorizzazione per la lettura della tabella MARA.
La condizione va passata nel campo OPTIONS[]-TEXT e, se è formata da più condizioni, queste vanno concatenate in una unica stringa e relazionate con l’operatore AND.
This website uses technical cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.