Scenario
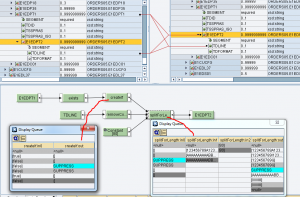
Mapping grafico.
Requisito
In un contesto di generazione IDoc verso ECC, occorre generare i segmenti di testo E1EDT01/E1EDT02 e/o E1EDP01/E1EDP02 partendo da una stringa in ingresso.
l’UDF splitForLength() è utile nella generazione dei segmenti di testo negli idoc sia nella sezione testata E1EDKT1/E1EDKT2 che in quella di posizione E1EDPT1/E1EDPT2
In particolare, l’UDF consente di generare tanti contesti E1ED*T2 quante sono le sottostringhe di src che si ottengono dividendola per la lunghezza ln.
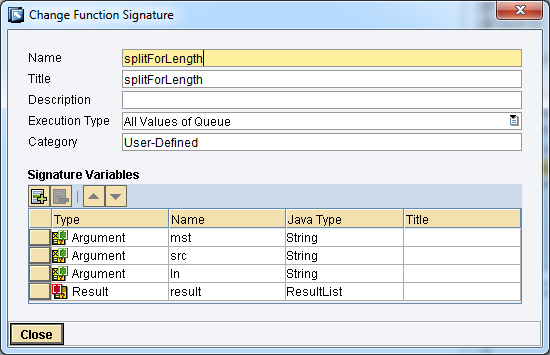
public void splitForLength(String[] mst, String[] src, String[] ln, ResultList result, Container container) throws StreamTransformationException{
/*
@Author: Nicola Martella | www.nick4name.eu
Genera un context (ResultList) sulla base dello splitting della stringa src in tante sottostringhe quante ne occorrono dividendola per la
lunghezza indicata in ln.
La funzione gestisce i contesti multipli su mst e src.
*/
AbstractTrace _trc = container.getTrace();
// _trc.addWarning(source.substring(s, s + len)); //*******************
int len = Integer.parseInt(ln[0]);
result.clear();
int isrc = -1;
for (int imst=0; imst < mst.length; imst++){
if (mst[imst].equals(ResultList.SUPPRESS)){
result.addSuppress();
} else if (mst[imst].equals(ResultList.CC)) {
//
} else {
isrc++;
String source = src[isrc];
if (!source.equals("")){
if (len >= source.length()){
result.addValue(source);
} else {
int e = source.length() / len;
e = ((source.length() % len) > 0 ? e + 1 : e);
int s = 0;
for (int i = 0; i < e; i++){
if (source.length() - s > len){
result.addValue(source.substring(s, s + len));
} else {
result.addValue(source.substring(s));
}
s += len;
}
}
result.addContextChange();
}
}
}
return;
}
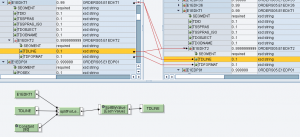
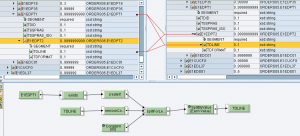
Implementazione per testi di testata

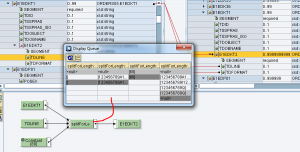
Questo genera le occorrenze di E1EDKT2 sulla base del numero di sottostringhe di TDLINE
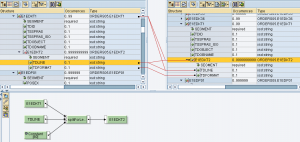
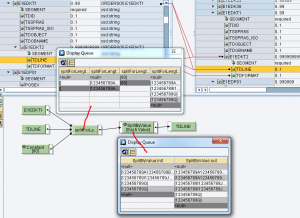
Questo, per ciascun contesto, effettua lo splitting di TDLINE in ingresso e scrive le sottostringhe prodotte nei campi TDLINE in uscita.
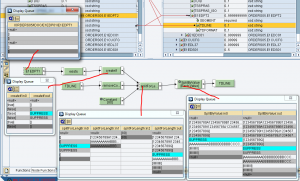
Implementazione per testi di posizione
Questo genera le occorrenze di E1EDPT2 sulla base del numero di sottostringhe di TDLINE
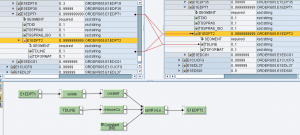
Questo, per ciascun contesto, effettua lo splitting di TDLINE in ingresso e scrive le sottostringhe prodotte nei campi TDLINE in uscita.
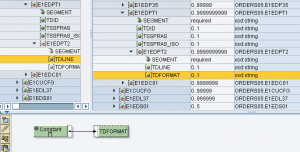
Nel seguente esempio, il contesto in entrata all’UDF – 1mo param, è così configurato:
E1EDP01 con testo (true)
E1EDP01 senza testo (false) -> SUPPRESS
E1EDP01 con testo (true)