Trace
AbstractTrace _trc = container.getTrace(); _trc.addWarning(var1);
public void removeSUPPRESS(String[] inp, ResultList result, Container container)
throws StreamTransformationException {
result.clear();
for (int i = 0; i < inp.length; i++) {
if (!(inp[i].equals(ResultList.SUPPRESS)) && !(inp[i].equals("")) && !(inp[i].equals(null))) {
result.addValue(inp[i]);
}
}
return;
}Rimuove gli elementi ResultList.SUPPRESS e <null> dal contesto.
Dato il seguente payload in inbound
<?xml version="1.0" encoding="UTF-8"?>
<ns0:MT_A xmlns:ns0="urn:develop:n4n.eu:SUPPRESS">
<row>
<KEY>FFX</KEY>
<DATA>A</DATA>
</row>
<row>
<KEY>AAA</KEY>
<DATA>B</DATA>
</row>
<row>
<KEY>AAA</KEY>
<DATA>C</DATA>
</row>
<row>
<KEY>FFX</KEY>
<DATA>D</DATA>
</row>
</ns0:MT_A>
occorre produrre in outbound un analogo payload con solo i row il cui KEY = ‘FFX’.
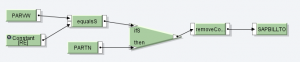
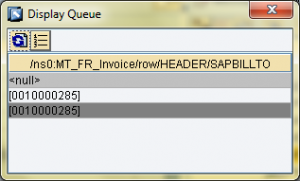
Dato il mapping sotto, si visualizzano le code sulla removeContext.
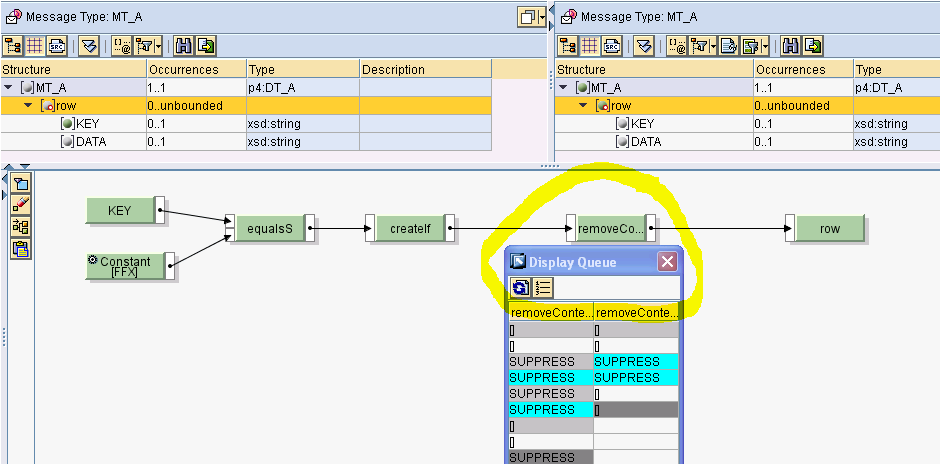
Si può constatare che la removeContext rimuove i contesti SUPPRESS (grigi), Change Context, e conserva i valori SUPPRESS (azzurri) corrispondenti agli elementi senza FFX.
dove

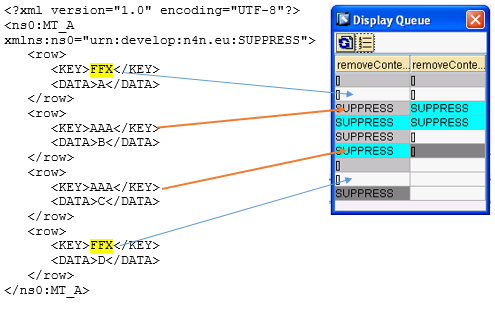
Aggiungendo removeSUPPRESS dopo la removeContext si produrrà il seguente risultato
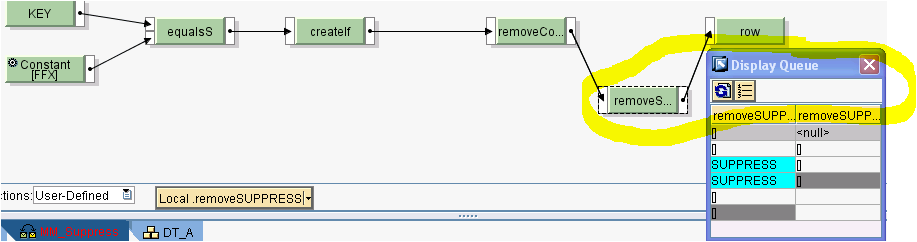
dove gli elementi SUPPRESS (azzurri) sono stati rimossi lasciando solo quelli relativi ai row con FFX.
public String safeSubstr(String value, int startPos, int length, Container container)
throws StreamTransformationException {
/*
* @Author: Nicola Martella | www.nick4name.eu La funzione ritorna la
* sottostringa di value a partire da startPos (in base 0) per la lunghezza
* length. Es1: value: "ABCDEFGHIJ" startPos=6 length=3 ret: "GHI" Se la
* posizione di length a partire da startPos eccede la lunghezza di value, viene
* ritornata la sottostringa a partire da startPos per tutta la lunghezza
* rimanente. Es2: value: "ABCDEFGHIJ" startPos=6 length=10 ret: "GHIJ" Se la
* posizione di startPos e' maggiore della lunghezza di value, viene ritornata
* una stringa vuota. Es3: value: "ABCDEFGHIJ" startPos=11 length=3 ret: "" Se
* value è null, viene ritornata una stringa vuota. Es4: value: null startPos=0
* length=3 ret: "" Se length e/o startPos sono < 0 vengono posti a 0.
*/
if (value == null)
return "";
if (length < 0)
length = 0;
if (startPos < 0)
startPos = 0;
int toPos = startPos + length;
if (toPos > value.length()) {
toPos = value.length();
}
if (startPos > value.length()) {
startPos = value.length();
}
return value.substring(startPos, toPos);
}Il numero di elementi in output è determinato dal numero di elementi dell’array, risultato della RemoveContext o della CollapseContext, e non dal numero di contesti, risultato della SplitByValue.
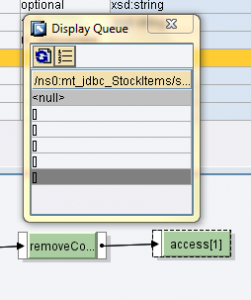 Determina 4 elementi in output
Determina 4 elementi in output
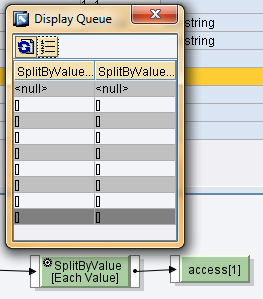 Determina un solo elemento in output e precisamente il primo
Determina un solo elemento in output e precisamente il primo
Questo snippet si applica quando, a fronte di due differenti contesti correlati fra loro, si vogliono ottenere più contesti che rappresentino la correlazione.
Un esempio può essere il contesto TESTI con testi in lingua diversa ed il contesto LINGUE DEI TESTI. Si vogliono ottenere tanti contesti quante sono le lingue e in ciascun contesto i testi per quelle lingue.
Il requisito è che il contesto LINGUE DEI TESTI sia ordinato e che gli item del contesto dei TESTI siano in corrispondenza con gli item del contesto LINGUE DEI TESTI.
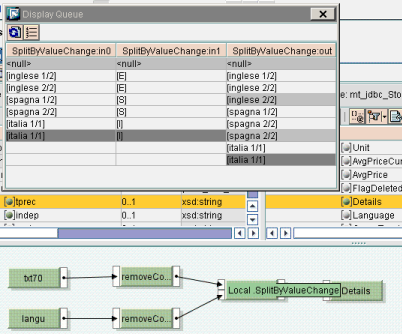
public void SplitByValueChange(String[] data, String[] criteria, ResultList result, Container container) throws StreamTransformationException{
/*
Dati due array in input, data e criteria, genera tanti contesti di data quante sono le rotture di livello di criteria.
Nessuno dei due array dev'essere vuoto o null e la dimensione di entrambi dev'essere la stessa.
*/
result.clear();
if( StringManager.isArrayNull(criteria) || StringManager.isArrayNull(data)) {
return;
}
if( criteria.length != data.length ){
return;
}
String t = criteria[0];
for (int i = 0; i < criteria.length; i++){
if(!criteria[i].equals(t)){
result.addContextChange();
t = criteria[i];
}
result.addValue(data[i]);
}
}Questo snippet è utile quando si vuole operare su un contesto applicando più filtri in cascata.
Nell’esempio sotto si vuole creare un contesto di “record 2” e, all’interno di questo, raggruppare in singoli sotto-contesti record 2 con la stessa lingua.

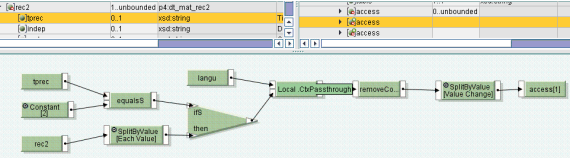
public String CtxPassthrough(String newContext, String currentContext, Container container)
throws StreamTransformationException{
/*
Consente di mantenere attivo un contesto, quello passato al parametro currentContext,
e contemporaneamente di generarne un altro passandolo al parametro newContext.
In output ritorna il parametro newContext senza alcuna trasformazione.
*/
return newContext;
}Dato un payload in ingresso riferito a più documenti occorre creare altrettanti documenti in output ciascuno dei quali deve avvalersi di uno o più numeratori, per le posizioni o altro, ed il/i numeratore/i deve resettarsi ad ogni nuovo documento.
UDF
In Attributes and Methods definire la variabile globale
int po_item = 0;
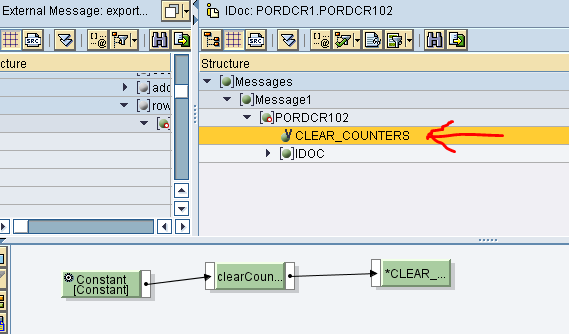
public String clearCounters(String dummy, Container container) throws StreamTransformationException{
po_item = 0;
pckg_no = 0;
return "";
}
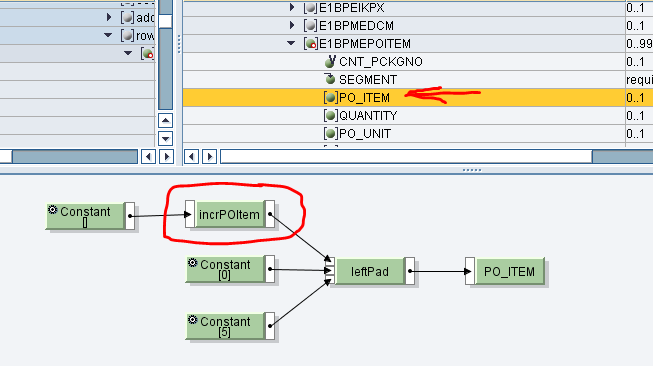
public String incrPOItem(String dummy, Container container) throws StreamTransformationException{
po_item += 10;
return new Integer(po_item).toString();
}
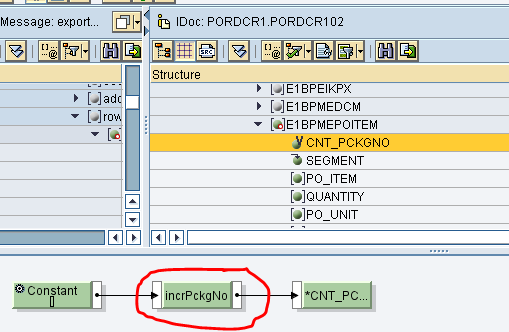
public String incrPckgNo(String dummy, Container container) throws StreamTransformationException{
pckg_no += 1;
return new Integer(pckg_no).toString();
}Mapping
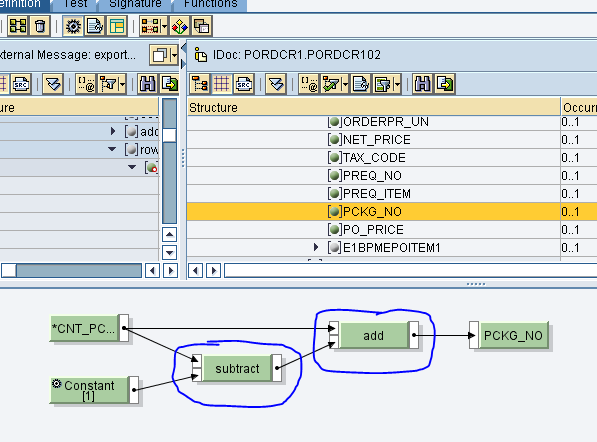
Reset dei contatori all’origine del nuovo documento
Incremento del contatore
Qualora l’output dell’udf debba essere utilizzato in più calcoli ma con il medesimo valore, occorre salvarlo in una variabile ed utilizzarlo nel modo seguente:
Incrementare un’unica volta il contatore
Utilizzare il contatore nei calcoli
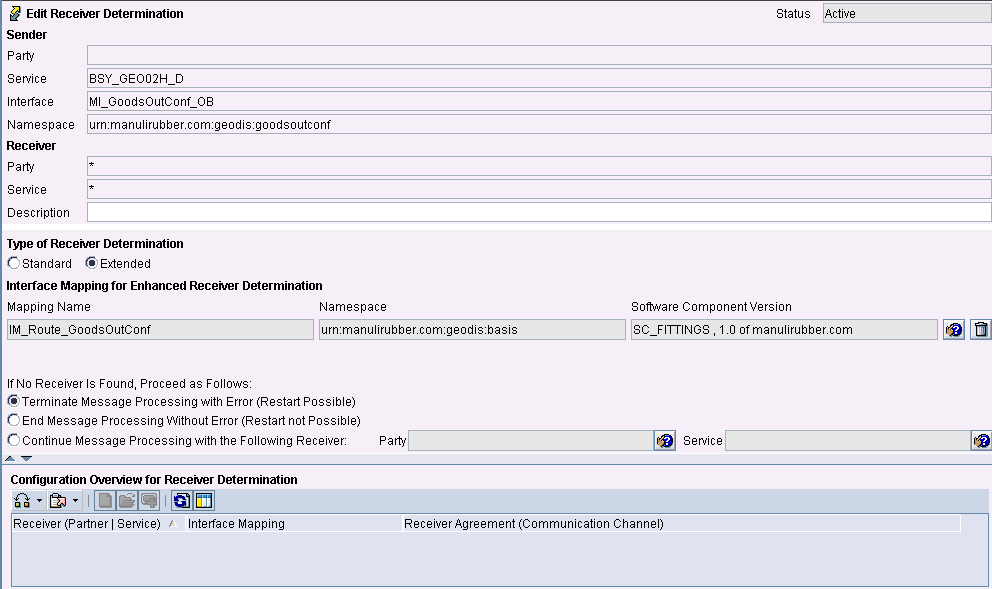
Determinare la Receiver Determination via mapping e referenziarlo tramite la Receiver Determination con il Type of Receiver Determination: Extended
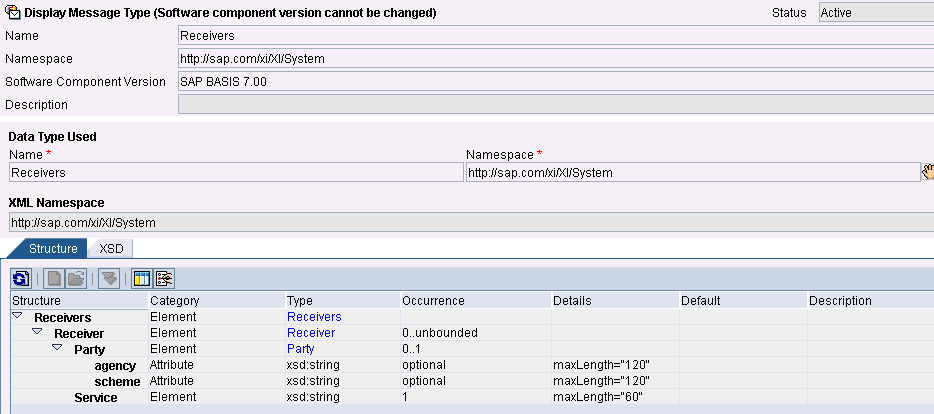
In ESR
Sender: arbitrario
Receiver: importare Receivers
Mapping
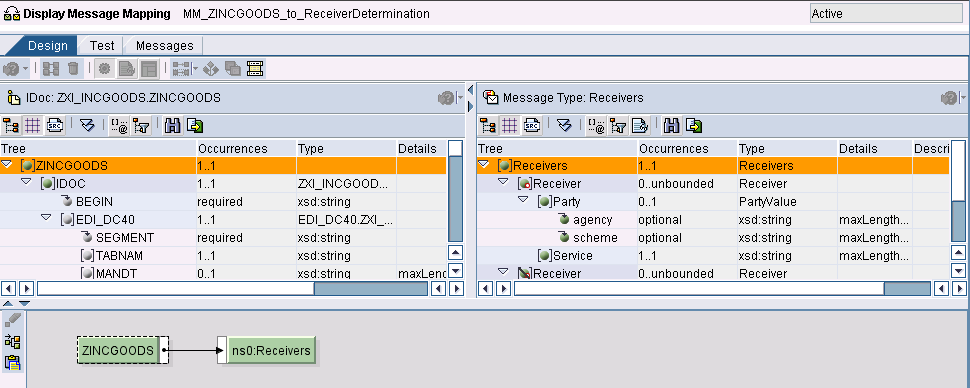
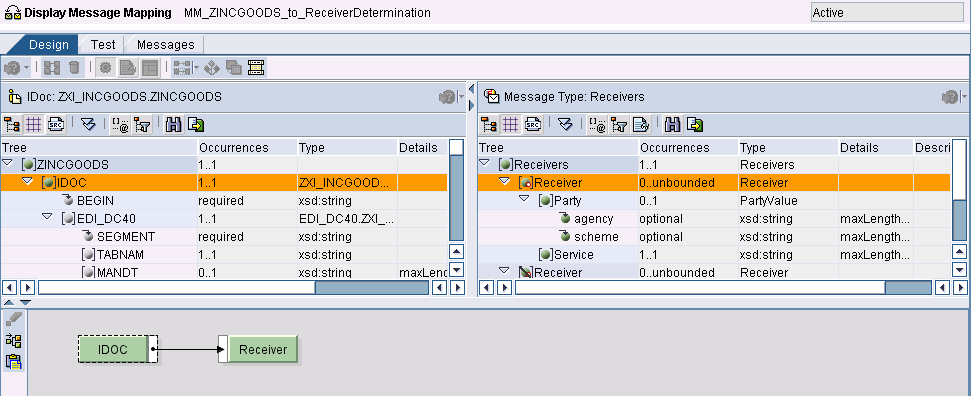
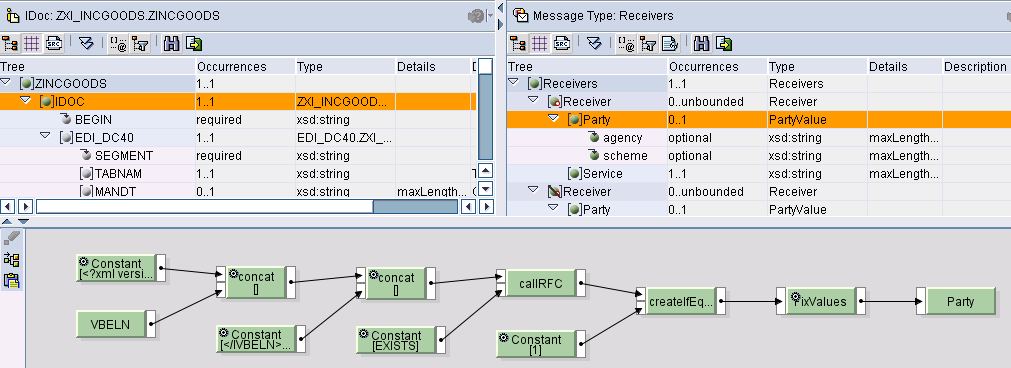
Qualora si debba determinare dinamicamente il Party, implementare l’opportuna logica (arbitraria) su questo nodo
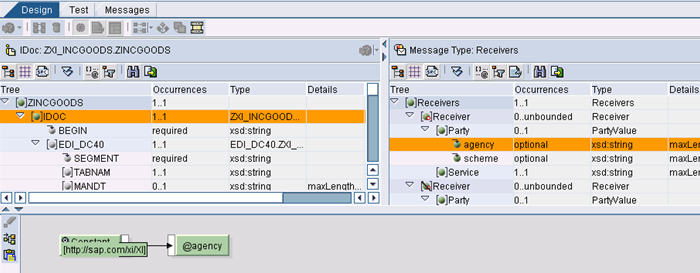
Valorizzare se è valorizzato Party
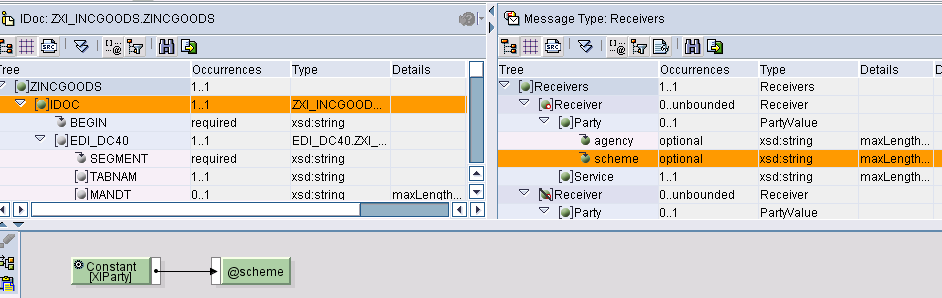
Valorizzare se è valorizzato Party
Per determinare dinamicamente il service implementare l’opportuna logica (arbitraria) su questo nodo
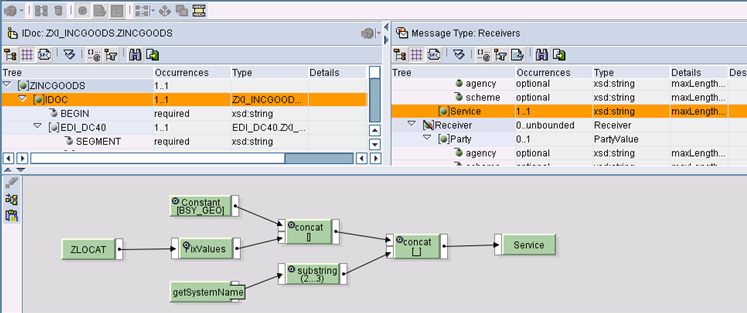
getSystemName() ritorna il contenuto della variabile d’ambiente SAPSYSTEMNAME presente sul server e ritorna il nome del sistema SAP
public String getSystemName(Container container){
String locale = System.getProperty("SAPSYSTEMNAME");
return locale;
}In uno scenario file to Idoc in cui nel mapping dell’idoc occorre modificare il signing in 1:unbounded, qualora fosse necessario implementare diversi mapping in cascata, per tutti i mapping dev’essere modificato il signing in 1:unbounded.
A livello di Operation Mapping il signing dev’essere 1:unbounded.
Operation Mapping
1° mapping
2° mapping
3° mapping (IDoc receiver)
Muovere il valore del campo solo se il campo qualificatore del record a cui il campo source appartiene assume un determinato valore.
Questo esempio funziona se l’output ha lo stesso numero di occorrenze dell’input.
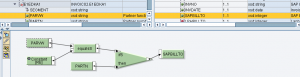
Se l’output ha occorrenza 1 e l’input occorrenza n, questo codice tenderà a mettere in output un solo elemento, quello con PARVW=RE. In realtà, dal momento che vengono generati tanti contesti, CONTEXT, quanti sono gli elementi in input, altrettanti contesti vengono passati in output – anche se quelli scartati perché non soddisfano la regola sono passati a SUPPRESS.
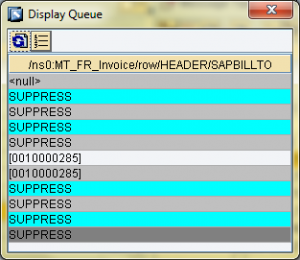
Per fare in modo che solo l’elemento valorizzato venga passato, occorre rimuovere i contesti tramite removeContexts.